本篇文章3303字,讀完約8分鐘
大模型端側部署正加速!AI PC等新物種熱度暴增,企業對于AI加速卡的關注度也水漲船高。
但是AI PC等端側設備中的AI加速卡如何做到可用、好用是一大難題,其需要兼顧體積小、性能強、功耗低才能使得端側設備承載大模型能力成為現實。
近日,清華系AI芯片創企芯動力科技面向大模型推出了一款新產品——AzureBlade L系列M.2加速卡。M.2加速卡是目前國內最強的高性能體積小的加速卡,其強大的性能使其能夠順利運行大模型系統。
M.2加速卡的大小僅為80mm(長)x22mm(寬),并已經實現與Llama 2、Stable Diffusion模型的適配。

具備體積小、性能強,且有通用接口的M.2加速卡成為助推大模型在PC等端側設備上部署的加速器。
從這一加速卡出發,芯東西與芯動力創始人、CEO李原進行了深入交流,探討了大模型產業發展至今產生的顯著變化,以及大模型在端側部署過程中,芯動力科技在其中扮演的角色以及手持的殺手锏是什么。
AI PC已經成為大模型落地端側設備的一個重要載體。
從去年年底至今,AI PC的熱潮正在涌起。前有英特爾啟動AI PC加速計劃、高通推出專為AI研發的PC芯片驍龍X Rlite、上周英偉達發布全新一代RTX 500和1000顯卡,支持筆記本電腦等端側設備上運行生成式AI應用……
根據市研機構IDC發布的最新報告,預估AI PC出貨量2024年逼近5000萬臺,到2027年將增長到1.67億臺,占全球PC總出貨量的60%左右。
AI PC這一新物種正在加速大模型的規模化落地。與此同時,擁有龐大參數規模的大模型也對端側設備可承載的算力提出了更高的需求。
在端側往往只有一個獨立設備。以PC為例,作為人們日常生活、工作的常用設備,其體積并不大且足夠輕便,因此需要AI加速卡足夠小且不會因體積犧牲性能上的優勢。以M.2加速卡的形式進入AI PC的市場就是很有優勢的產品形態。
可以看到,當下大模型的發展路線不再唯參數論,越來越多參數規模小性能強大的模型出現,如開源的Llama 2模型系列參數在70億到700億不等,為大模型在端側的落地提供了機會。
即便如此,大模型想要成功部署在端側對于芯片玩家而言仍然具有挑戰,需要其突破端側設備有限的計算和存儲能力,因此芯片玩家亟需找到芯片體積小與性能強大的平衡點。
李原談道,端側設備還有一大特點是,GPU是其最主要的元件。這背后的風險在于,企業全部圍繞GPU來做設備,就會造成一旦產品的開發周期變長,其未來的開發路線會受到一定限制。由于邊緣設備上接口的可選擇性不多,很多設備需要針對不同的芯片進行接口定制,企業就需要承擔接口受限的風險。
這些新的變化及需求為這家GPGPU創企帶來了新的機遇。
芯動力科技的AzureBlade L系列M.2加速卡,就是面對這一市場變化的最佳解決方案之一。
M.2加速卡搭載了4個DDR內存,總容量達到16GB,除了支持傳統的視覺網絡,如YOLO等,現在更已經實現了與Llama 2、Stable Diffusion等模型的適配。李原解釋道,M.2加速卡目前可以支持70億、130億參數規模的Llama 2模型,以及最多可以支持300億。目前,70億參數規模的Llama 2在M.2加速卡上的計算速度可達到十幾tokens每秒。
正與當下端側的玩家承接大模型能力的核心痛點相對應,M.2加速卡的優勢正是體積小、性能強,功耗低。
李原談道,一般的GPU,NPU如果要處理大模型,因為算力要求高、功耗大,芯片面積也會比較大,很難集成在端側設備狹小的空間內。M.2加速卡的大小僅為80mmx22mm,剛好能做到這一點。
達到這一優勢的關鍵在于,芯動力科技為M.2加速卡集成了一顆芯片——AE7100,這顆芯片以17mmx17mm的面積實現了32 TOPs的算力與60GB/s的內存帶寬。
 為了打造這顆足夠薄且小的芯片,芯動力科技研發了一種創新的封裝方案。他們一開始就在這個方向布局,去掉了芯片中的ABF材料,在無基板的情況下制造完成了芯片,還能滿足其散熱需求。“這也是我們第一次嘗試這一封裝工藝,并打造出了這顆業界最小、最薄的GPU。”李原說。
為了打造這顆足夠薄且小的芯片,芯動力科技研發了一種創新的封裝方案。他們一開始就在這個方向布局,去掉了芯片中的ABF材料,在無基板的情況下制造完成了芯片,還能滿足其散熱需求。“這也是我們第一次嘗試這一封裝工藝,并打造出了這顆業界最小、最薄的GPU。”李原說。
由于端側設備的接口有限,芯動力科技為M.2加速卡選擇了更為普及的閃存硬盤接口,這種接口已經普遍存在于PC等設備中,因此更容易被企業所接受,無需針對芯片進行接口定制就能快速實現相應的功能。
目前已經有諸多客戶注意到了M.2加速卡,芯動力科技M.2加速卡的通用接口可以幫助企業規避定制風險,同時為其適配市面上的不同產品擴大可選擇性。
與此同時,這一加速卡采用完全可編程設計,兼容CUDA+ONNX,可以廣泛應用于AI PC、機器視覺、泛安防、內容過濾等領域。
在當下大模型逐漸邁向端側設備、AI PC等新物種的熱潮初現,支撐芯動力科技能夠迅速推出創新的M.2加速卡,其關鍵基石在于——可重構并行處理器架構(RPP)。這正是M.2加速卡的核心AE7100背后的殺手锏。
RPP架構是針對并行計算設計的芯片架構,芯動力將其稱作“六邊形戰士”。這一架構既結合了NPU的高效率與GPU的高通用性優勢,更具備DSP的低延時,可滿足高效并行計算及AI計算應用,如圖像計算、視覺計算、信號處理計算等,大大提高了系統的實時性和響應速度。
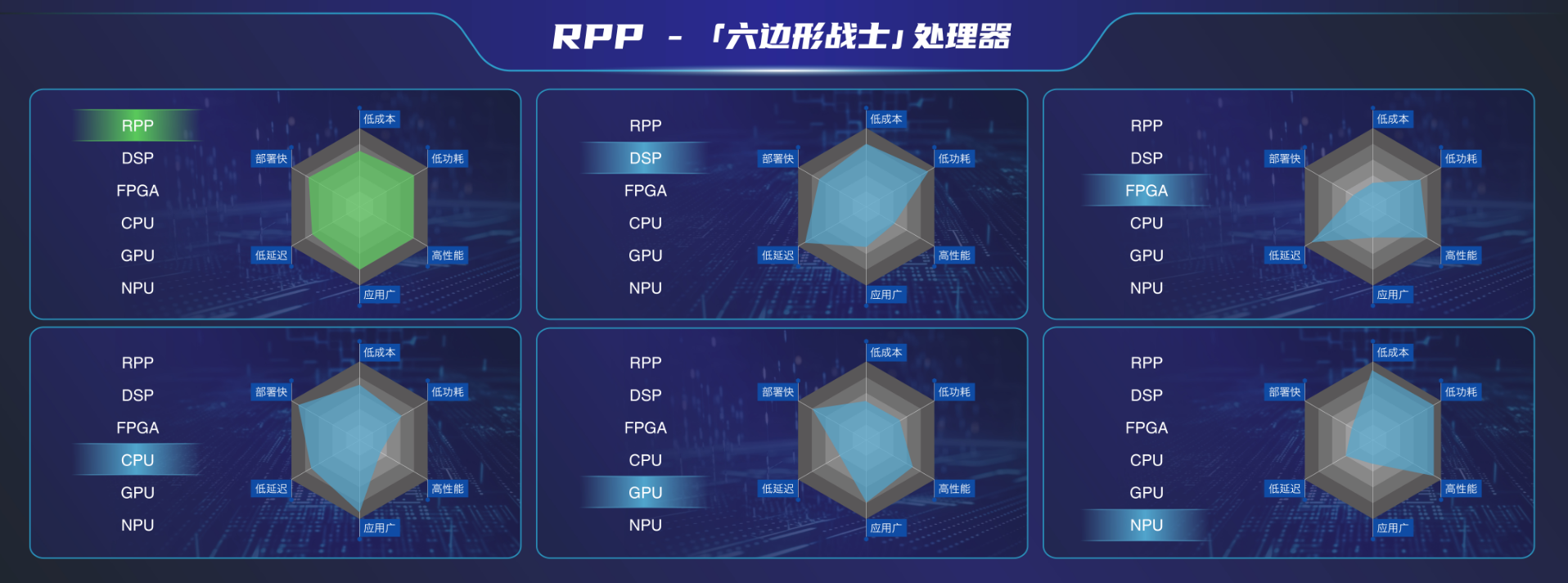
芯動力同樣制程下的GPGPU芯片,與英偉達相比,在一些場景下性能提高達50%,且Core的面積為類似芯片的1/7,功耗僅為其1/2-1/3。
對這一架構的探索正是他們成立公司的最根本原因。芯片行業的發展周期很長,因此芯動力科技需要在保證芯片性能的同時,能適應5、6年之后市場的變化,這樣才能在AI PC這樣的機會出現時,迅速抓住機遇,打造出具有顯著優勢的產品。
對RPP架構的探索可以追溯到英偉達提出GPGPU新概念前后。彼時,芯動力創始團隊就開始探索如何在發揮GPU并行計算能力和通用性優勢的同時,通過引入其他類架構的長處,研發出能更好平衡性能、功耗、成本、延遲、部署速度的硬件。
因此,在2011年到2016年間,他們探索出獨創的將NPU的高效率與GPU的高通用性相結合的創新架構,RPP架構應運而生。
芯動力科技將產品的開發周期定義為兩個階段,芯動力科技做的就是芯片的研制、基礎軟件研發,這樣一來,針對企業的需求在這塊基本成型的芯片上進行研發,只需要兩三個月,就能達到產品性能,大大縮短芯片應用的時間周期。
這背后的考量就是芯片的市場推廣。他補充說,目前AI發展處于早期,其落地的產品量相比于其他傳統行業的設備而言并不算多,因此其產品定義仍然在快速變化中。以RPP架構為核心的產品出現,能前瞻性地瞄準通用性需求,滿足芯片在更廣泛場景下的應用,這就相當于他們面對最后的產品已經走了70%的路。
面向當下的市場變化,M.2加速卡已經快速向客戶實現出貨。目前M.2加速卡面向的客戶主要為AI PC、工業視覺以及AI服務器廠商。目前,M.2加速卡已經向基因檢測、AI服務器客戶出貨,AI PC廠商仍在進行產品的調校。
可以確定的是,芯動力科技的這一創新產品正讓大模型在端側迸發出無限的想象力。
大模型熱潮為國內GPGPU公司帶來諸多機遇,大模型在應用端的計算需求對于國內創企而言是一個巨大的機會。
對于芯動力科技而言,其創辦之初就開始前瞻性地打造更加通用的產品,以RPP架構為核心打造產品適配企業客戶更通用的需求,能更靈活應對復雜多變的市場趨勢。
隨著M.2加速卡規模出貨、AI PC這一新物種的大規模量產,大模型在端側將會的發展將會加速。芯動力科技也在大模型帶來的產業變革下,熱切尋找市場機遇。
可以看出,當下想要抓住產業機遇,核心的技術積累與前瞻性的技術布局更為關鍵。
特別聲明:本站的所有文章版權均屬于
自動化網,未經本網授權不得轉載、摘編或利用其它方式使用上述作品,已經本網授權的文章,應在授權領域內應用,并注明來源為:“自動化網”。。
標題:大模型端側部署激戰!GPGPU創企亮出AI加速卡,小體積跑70億參數大模型? ??地址:http://www.ggp9.com/article/20954.html
